
How to Scrape 1 Million Tweets - Without the Twitter API
We scraped 1 million tweets that mentioned the hashtag 'Islam' in about 12 hours.


(Generated By Dall-E: “Thousands of Tweets Raining Down on a City Skyline”)
Why Twitter Matters
Twitter is one of the most important social media platforms out there used by individuals, companies, activists, media, and governments. In fact, some would argue it’s the world’s defacto town square (Wall Street Journal 2022). Twitter played a pivotal role in the unfolding of world-changing events such as the Arab Spring, Black Lives Matter, #MeToo, controversial elections, and the COVID-19 Pandemic.
The micro-blogging approach allows people to send short messages forcing them to focus on concision and quality, allowing for ideas to spread quickly through highly dense networks. It’s a great way to connect with like-minded individuals and form communities in ways that other platforms like Facebook, Youtube, and perhaps even Reddit lack.
Every second, on average, around 6,000 tweets are tweeted on Twitter […], which corresponds to over 350,000 tweets sent per minute, 500 million tweets per day and around 200 billion tweets per year. (Internet Live Stats)
With so much information being generated and its ability to provide important insights on humanity, analyzing (and therefore scraping) Twitter data is an important function of many researchers, analysts, and data scientists.
Say Bye-Bye to the Twitter API
Unlike other social media platforms, like Facebook and LinkedIn, which take a ‘walled garden’ approach to data, Twitter created an API to allow developers, academics, and hobbyists alike to access data. Anyone could set up a a Twitter Developer account and get access to a free plan and start scraping data. There were additional plans available with higher rate limits, access to more tweets, and went farther back in time among other things.
Unfortunately, Twitter’s transparent approach looks like it is coming to an end with Elon Musk’s purchase of the company. In October 2022, Musk bought the company at an over-valued price, putting significant strain on the company’s finance. In spite of laying off over 75% of the staff, selling off furniture, and not paying Twitter’s bills, the company’s financial straits were still strained. Last month, Musk announced that significant changes were coming to the Twitter API including the removal of the free option (The Guardian 2023).
What’s a researcher to do? Luckily, there are alternatives to the Twitter API for scraping tweets such as SNScrape. We’ll walk you through exactly how to do so below.
SNScrape: Free, Fast, and Open Source
Unfortunately, there’s little to no documentation available for SNScrape in the github project itself. While there are ample tutorials on Youtube and Medium, a lot of them are out of date. In this post, we’ll show you how to scrape one million tweets related to a hashtag by using SNScrape instead of the Twitter API.
Sample Project: Building a Labeled Dataset to Train Machine Learning Models to Quickly Identify Hate Speech and Calls to Violence Against Muslims Online
We ran a script that doesn’t use Twitter’s API as recently as February 2023 and were able to successfully scrape 1,000,000 tweets that used the hashtag “Islam” in about 12 hours. Our reason for downloading the million tweets is to try and build a labeled dataset of tweets that are classified as “Islamophobic” or “Not Islamophobic” so developers can use it to train machine learning models.
Unfortunately, while there are many datasets and machine learning models around hate speech or violent speech, they are usually too general to be useful. While tracking Islamophobia around the world, we noticed that many social media platforms weren’t censoring slurs and calls to ethnically cleanse Muslims because their algorithms are likely not sophisticated enough.
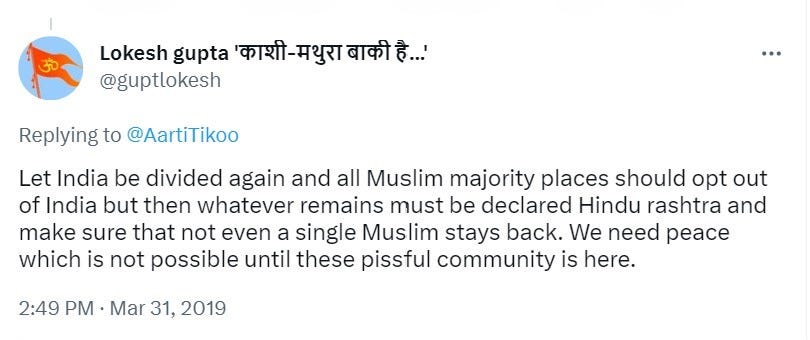
We found tweets in India where users openly were calling to kill Muslims or do population transfers in English that were just sitting around undetected because they used words like “Pissful” (i.e. “Peaceful” Muslims), Abdel, Mohammedan, etc.
Training a model usually requires hundreds of thousands of datapoints. We aimed for 1 million in case we needed to clean up the data. Below is our walk through of how to do so step by step.
Datapoints from a Single Tweet
While a tweet itself may be limited to 280 characters, quite a bit of data can be generated from it.
Here’s a list of the types of data we can collect for each tweet that mentions a hashtag.
.date: date and time of the tweet
.url: a link to the tweet
.content: the text of the tweet, includes emojis and various languages
.renderedContent: A rendered tweet, on the other hand, is how the tweet appears on a particular platform or device. This includes the layout, design, and any additional elements that may be added by the platform, such as retweet and like buttons, profile pictures, and reply threads.
.id: the unique numerical ID of that tweet
.user.username: the username as it appears in the URL (ex: twitter.com/username)
.user.displayname: the display name as it appears on the front end (Ex: User Name XoXo)
.user.id: the unique numerical ID of the user that sent the tweet
.user.description: the user’s description as it appears in the profile
.user.verified: whether the user is verified or not
.user.created: the datetime of when the user account was created
.user.followersCount: the number of the user’s followers
.user.friendsCount: the number of the user’s friends (i.e. who they are following)
.user.statusesCount: the total number of tweets the user has sent
.user.location: the user’s location if they provided one in their profile
.user.descriptionUrls: a list of URLs mentioned in the user’s profile description
.user.linkUrl: the URL if a user has one in their profile
.user.profileImageUrl: a link to the user’s profile image
.user.profileBannerUrl: a link to the user’s banner image (the image behind the profile image)
.replyCount: the number of replies to the tweet
.retweetCount: the number of retweets of the tweet
.likeCount: the number of likes to the tweet
.quoteCount: the number of quoted tweets from the tweet
.lang: the language of the tweet
.source: the device used to make the tweet (ex: Twitter Web App, Twitter for iPhone, Twitter for Android, iPad, etc)
.retweetedTweet: If the tweet is a retweet of another tweet, the original tweet
.quotedTweet: If the tweet is a quoted tweet, the original tweet
.mentionedUsers: If the tweet mentions any users (ex: @username1, @username2)
.hashtags: If the tweet mentions any hashtags (ex: #hashtag1, #hashtag2)
Walkthrough: Overview
Here’s an overview of all the steps needed to scrape the tweets.
Install the necessary libraries
Import the libraries
Create a variable to store the hashtag
Create a variable to store the hashtag, hashtag number target, and filename
Create a list to store the tweets in
Create variables to track the count and sleep intervals
Run a for loop to scrape the tweets and append the list with each tweet
Ingest the data from the list into a pandas dataframe
Write the pandas dataframe to the .csv
Step 1: Install the necessary libraries
To begin, we will need to install two Python packages: snscrape and pandas. You can install them using pip commands in your command terminal (make sure to use admin privileges):
# Install Libraries
pip install snscrape
pip install pandasStep 2: Import the libraries
Once you have installed the required libraries, it's time to start writing the code. Start by importing the required libraries in your IDE. You won’t need to install the csv, datetime, or time libraries as those come with Python by default.
import csv
from datetime import date
import pandas as pd
import snscrape.modules.twitter as sntwitter
import timeStep 3: Create a variable to store the hashtag, hashtag number target, and filename
Next, we will set up the hashtag query we want to scrape, the maximum limit of the number of tweets to scrape, and create a filename using the number of tweets along with the current date. When you start scraping data, you’ll likely do it over and over again and will generate a lot of files. Therefore, it’s important to be able to set a filename that’s descriptive so you can tell it all apart. We will also generate the filename with the current date and time.
hashtag_query = "islam"
limit = 1000000
limit_as_string = str(limit)
filename = "your_folder_path\_" + limit_as_string + "_tweets_" + hashtag_query + "_" + str(date.today().strftime("%m-%d-%y")) + ".csv"
print("Filename Generated: ", filename)Step 4: Create a list to store the tweets in
We will create an empty list to store the tweets, and a variable to store the Twitter profile URL to concatenate the username with it to get the full URL.
tweets = []
twitter_profile_url = "https://twitter.com/"Step 5: Create variables to track the count and sleep intervals
We will also create a variable to count the number of tweets we have scraped, and a variable to set the time interval for the script to sleep. We will set it to 15 minutes, so the script doesn't get blocked by Twitter. (Fun Fact: I accidentally commented out the sleep function so when I scraped 1,000,000 tweets, I did so without being blocked).
count = 0
sleep_time = 900Step 6: Run a for loop to scrape the tweets and append the list with each tweet
We will use a for loop to iterate over the TwitterSearchScraper class from snscrape. The class allows us to search for tweets with a specific hashtag or query. We’ll also print the count so you can see how many tweets have been scraped through the for loop. We will break the loop once we have reached the limit of tweets we want to scrape.
for tweet in sntwitter.TwitterSearchScraper(hashtag_query).get_items():
if len(tweets) == limit:
break
else:
#print(tweets)
count += 1
if count % 2000 == 0:
print("Going to sleep for ", sleep_time/60, " minutes")
time.sleep(sleep_time)
tweets.append([
tweet.date,
tweet.url,
tweet.content,
tweet.renderedContent,
tweet.id,
tweet.user.username,
tweet.user.displayname,
tweet.user.id,
twitter_profile_url + tweet.user.username,
tweet.user.description,
tweet.user.verified,
tweet.user.created,
tweet.user.followersCount,
tweet.user.friendsCount,
tweet.user.statusesCount,
tweet.user.location,
tweet.user.descriptionUrls,
tweet.user.linkUrl,
tweet.user.profileImageUrl,
tweet.user.profileBannerUrl,
tweet.replyCount,
tweet.retweetCount,
tweet.likeCount,
tweet.quoteCount,
tweet.lang,
tweet.source,
tweet.retweetedTweet,
tweet.quotedTweet,
tweet.mentionedUsers,
tweet.hashtags
])
print("Scraped Tweets:", count)Step 7: Ingest the data from the list into a pandas dataframe
Next, we’ll create a Pandas dataframe called ‘df’ and create a column name for eacho f the parameters scraped from the scraper argument. You don’t need to use twitter’s parameters for the column names, you can make up your own that you find are a bit more helpful to you. However, I would recommend using an underscore in the column headings so you can access them later with Pandas, otherwise you’ll have to use the position of that column, which is a bit more work and can cause issues later on if you add or remove columns.
df = pd.DataFrame(tweets, columns=[
'date',
'tweet_url',
'tweet_content',
'tweet_rendered_content',
'tweet_id',
'user_name',
'display_name',
'user_id',
'concatenated_profile_url',
'user_description',
'verified',
'user_profile_created',
'user_follower_count',
'user_friend_count',
'user_statuses_count',
'user_location',
'user_description_url',
'user_profile_url',
'user_profile_image_url',
'user_profile_banner_url',
'tweet_reply_count',
'tweet_retweet_count',
'tweet_like_count',
'tweet_quote_count',
'tweet_language',
'tweet_source',
'rt_original_tweet_id',
'quoted_tweet_original_tweet_id',
'tweet_mentioned_users',
'tweet_hashtags'
])
print(df)Step 8: Write the pandas dataframe to the .csv
Last but not least, we write the pandas dataframe to a .csv.
df.to_csv(filename)Voila! 1 Million Tweets!
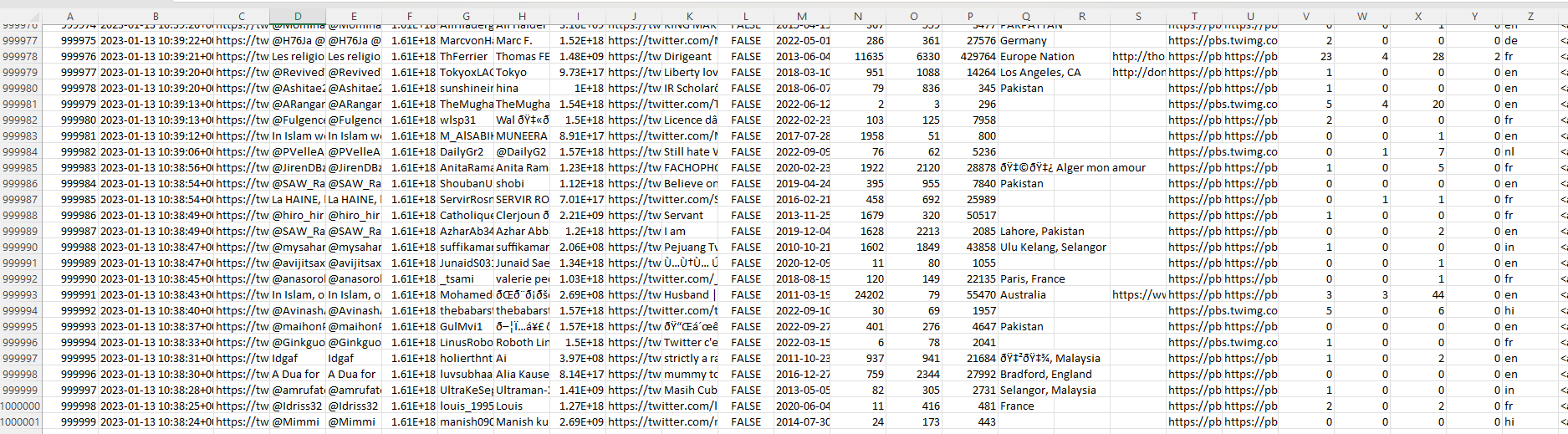
It took us about 12 hours to scrape a million tweets, but it worked! Here’s the finished product if you want to take a look at what the output looks like:
Resources
Full Project Code (Github Repo)
1,000,000 “Islam” Tweets Dataset CSV (Dropbox Public Link)